Quantifying London Traffic Dynamics for Air Pollution Estimation
Open-source library to automate collection of live traffic video data and extraction of descriptive traffic statistics. 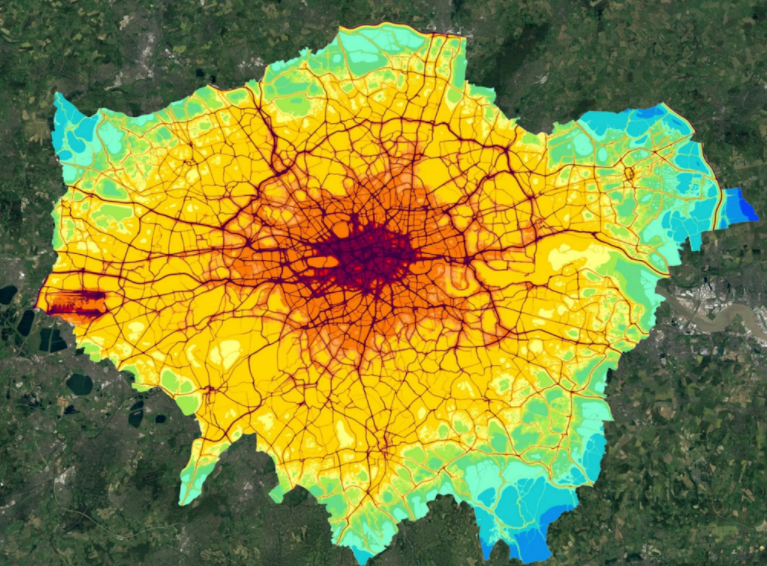 Read more
Read more

Open-source library to automate collection of live traffic video data and extraction of descriptive traffic statistics. Read more
Published in HDSR, 2020
We partially reverse-engineer the COMPAS model for recidivism prediction. Read more
Citation: Rudin, Cynthia and Wang, Caroline and Coker, Beau (2020). "The Age of Secrecy and Unfairness in Recidivism Prediction." Harvard Data Science Review.
Download here
Published in Journal of Quantitative Criminology, 2022
We design various interpretable machine learning models to predict criminal recidivism. Read more
Citation: Caroline Wang*, Bin Han*, Bhrij Patel, Feroze Mohideen, Cynthia Rudin (2022). "In pursuit of interpretable, fair and accurate machine learning for criminal recidivism prediction." Journal of Quantitative Criminology.
Download here
Published in AAAI, 2023
We propose DM$^2$, an algorithm that allows a team of agents to perform cooperative tasks by independently imitating corresponding experts agents from a team of experts. Read more
Citation: Caroline Wang*, Ishan Durugkar*, Elad Liebman*, Peter Stone. "DM$^2$: Distributed Multi-Agent Reinforcement Learning via Distribution Matching." AAAI 2023.
Download here
Published in AAMAS, 2023
We propose D-Shape, an RL+IL algorithm that allows learning from suboptimal demonstrations while retaining the ability to find the optimal policy with respect to the task reward. Read more
Citation: Caroline Wang, Garrett Warnell, Peter Stone (2023). "D-Shape: Demonstration Shaped Reinforcement Learning." AAMAS 2023.
Download here
Published in AAAI, 2024
We introduce Causal Bisimulation Learning (CBM), a method that learns the causal relationships in the dynamics and reward functions for each task to derive a minimal, task-specific abstraction. Read more
Citation: Zizhao Wang*, Caroline Wang*, Xuesu Xiao, Yuke Zhu, Peter Stone (2024). "Building Minimal and Reusable Causal State Abstractions for Reinforcement Learning." AAAI 2024.
Download here
Published in NeurIPS, 2024
Existing paradigms for multi-agent coordination are limited by assuming that either all agents are controlled (e.g. the typical cooperative MARL algorithm), or that only a single agent is controlled (ad hoc teamwork / zero shot coordination). We pose the N-Agent Ad Hoc Teamwork (NAHT) problem to the community, to lift these restrictions and pave the path towards more open multi-agent learning paradigms. Read more
Citation: Caroline Wang, Arrasy Rahman, Ishan Durugkar, Elad Liebman, Peter Stone. "N-Agent Ad Hoc Teamwork." NeurIPS 2024.
Download here
Published in arXiv preprint arXiv:2505.23686, 2025
We formulate ad hoc teamwork as an open-ended learning process between a regret-maximizing teammate generator and an ad hoc teamwork agent. Read more
Citation: Caroline Wang, Arrasy Rahman, Jiaxun Cui, Yoonchang Sung, Peter Stone. "ROTATE: Regret-driven Open-ended Training for Ad Hoc Teamwork." arXiv preprint arXiv:2505.23686.
Download here
Published in arXiv preprint arXiv:2602.10324, 2026
We employ AlphaEvolve to discover interpretable models from data, revealing that frontier LLMs can be capable of deeper strategic behavior than humans in iterated rock-paper-scissors. Read more
Citation: Caroline Wang, Daniel Kasenberg, Kim Stachenfeld, Pablo Samuel Castro (2026). "Discovering Differences in Strategic Behavior Between Humans and LLMs." arXiv preprint arXiv:2602.10324.
Download here
Published in Workshop on Multi-Agent Learning and Its Opportunities in the Era of Generative AI, 2026
We introduce JaxAHT, the first open-source, JAX-based library designed to accelerate and standardize the Ad Hoc Teamwork research lifecycle using hardware acceleration. Read more
Citation: Caroline Wang, Rolando Fernandez, Jiaxun Cui, Johnny Liu, Aditya Madhan, Zhihan Wang, Lingyun Xiao, Di Yang Shi, Arrasy Rahman, Peter Stone (2026). "JaxAHT: A JAX-Based Library for Ad Hoc Teamwork." Workshop on Multi-Agent Learning and Its Opportunities in the Era of Generative AI.
Download here
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown! Read more
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field. Read more
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post. Read more
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post. Read more